Utilizando Milvus na Magalu Cloud
Milvus é um banco de dados vetorial open-source projetado especificamente para armazenar, indexar e buscar grandes volumes de dados não estruturados, como imagens, vídeos, textos, entre outros, por meio de embeddings (representações vetoriais).
Existem 3 maneiras de utilizar o milvus:
-
Milvus Lite: uma versão do milvus que pode ser utilizada atravez do SDK python, onde os dados são armazenados em um arquivo, é recomendado para criação de prototipos utilizando milvus ou com o uso de um volume de até 1 milhão de vetores.
-
Milvus Standalone: uma versão do milvus para utilizar em um único servidor, ele empacota todos os recursos necessários em uma imagem docker, facilitando no processo de deploy. Caso não queira usar kubernetes em produção, está é uma ótima opção, desde que o servidor tenha memória suficiente para lidar com o volume de dados e consultas. Essa versão é recomendada para volumes de até 100M de vetores.
-
Milvus Distributed: uma versão distribuida do milvus, onde a ingestão de dados, consulta, e criação de index são processadas separadamentes por nós isolados, possibilitando um escalamento quando necessário.
Para os exemplos que serão apresentados a seguir, será utilizado a versão distribuida do Milvus, porém, a versão Standalone também é compativel com a Magalu Cloud.
Deploy
Neste guia, serão apresentados duas maneiras de implantar o Milvus em um cluster na Magalu Cloud:
Manual – utilizando Helm
Automática – utilizando Terraform
Para isso, será utilizado um cluster com um node pool do tipo Genérico Médio, contendo três nós.
Se você deseja estimar os recursos necessários para sua aplicação, o Milvus disponibiliza uma calculadora de recursos. Basta inserir algumas informações sobre sua aplicação, e ela estimará a quantidade de CPU, RAM e armazenamento necessários.
Criando Cluster na Magalu Cloud.
Para seguir com esse guia, é necessário criar um cluster com três nodes do tipo Genérico Medium.
Configurando Milvus.
Para configurar o Milvus, primeiro é necessário baixar os arquivos de configuração padrão do Milvus. Para isso, será utilizado o Helm. Execute os seguintes comandos para instalar o Helm e adicionar os repositórios do Milvus:
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
helm repo add milvus https://zilliztech.github.io/milvus-helm/
helm repo add zilliztech https://zilliztech.github.io/milvus-helm/
helm repo update
Em seguida, dentro do diretório em que deseja trabalhar, execute o comando abaixo para baixar os arquivos de configuração. Esse
comando criará um diretório chamado milvus, que conterá os arquivos de configuração, entre eles o values.yaml:
helm pull milvus/milvus --untar
Abra o arquivo milvus/values.yaml. Nele estarão todas as possíveis configurações. Procure pela seção referente ao service e substitua ou ajuste para que fique conforme o exemplo abaixo:
service:
type: LoadBalancer
port: 19530
portName: milvus
nodePort: ""
annotations: {}
labels: {}
externalIPs: []
loadBalancerSourceRanges:
- 0.0.0.0/0
Esse ajuste criará um service para expor os serviços necessários para acessar o Milvus.
Ainda no arquivo values.yaml, localize a seção externalS3 e ajuste-a com suas credenciais da Magalu Cloud e informações do bucket, conforme o exemplo:
externalS3:
enabled: true
host: "br-se1.magaluobjects.com"
port: "443"
accessKey: "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
secretKey: "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
useSSL: true
bucketName: "bucket_name"
cloudProvider: "aws"
Como os dados serão armazenados no OBJS, é necessário desativar o MinIO para evitar a criação de pods desnecessários. Para isso, no mesmo arquivo values.yaml, localize a seção minio e define o campo enabled como false:
minio:
enabled: false
Após realizar essas alterações, o Milvus estará configurado para utilizar o Object Storage da Magalu Cloud como armazenamento e expor seus serviços conforme desejado.
Realizando Deploy
Para fazer deploy do milvus no kubernetes, basta executar o comando abaixo passando o kubeconfig do cluster.
helm --kubeconfig=kubeconfig.yaml upgrade --install milvus milvus/milvus -f milvus/values.yaml
Pré Requisitos
Para realizar a construção do cluster na MGC e o deploy do Milvus com terraform, é necessário que MGC CLI esteja instalado em sua máquina e que sua conta esteja autenticada.
Configurando Milvus
Primeiramente, é necessário baixar o template que contém os códigos necessários para realizar o deploy do Milvus na Magalu Cloud.
O template possui cinco arquivos principais:
-
version.tf – Define os provedores necessários para a execução do Terraform.
-
variables.tf – Define variáveis utilizadas nos códigos, como o flavor do nodepool, a quantidade de réplicas, entre outros parâmetros.
-
main.tf – Contém as instruções para a criação do cluster na Magalu Cloud e do nodepool. Ao final da execução, gera um arquivo kubeconfig.yaml, que é utilizado para se conectar ao cluster.
-
values.yaml.tpl – Template contendo as configurações do Milvus.
-
secrets.tfvars.example – Contém um exemplo das variáveis necessárias para a execução.
-
milvus.tf – Define as instruções para o deploy do Milvus, utilizando o arquivo values.yaml para configurar o ambiente, como a quantidade de réplicas de cada serviço e o tipo de storage a ser utilizado.
Após baixar os arquivos, copie o secrets.tfvars.example mantendo como o nome "secrets.tfvars". Após isso, abra o arquivo e preencha accessKey e secretKey com as informações da sua conta na Magalu Cloud, host com o Endpoint que deseja usar e o nome do bucket que o Milvus irá utilizar para guardar os dados.
Realizando Deploy
Com o Milvus configurado, execute o seguinte comando para iniciar o Terraform:
terraform init
Em seguida, verifique se está tudo correto com os arquivos de configuração executando:
terraform plan -var-file="secrets.tfvars"
Se não houver erros, prossiga com o comando abaixo para iniciar a criação do cluster e, em seguida, o deploy do Milvus.
terraform apply -var-file="secrets.tfvars" -auto-approve
Esse processo pode levar alguns minutos. Na etapa final, o Helm provider pode exibir um erro durante o deploy, mas isso não significa, necessariamente, que o Milvus não foi instalado corretamente. Após a conclusão, prossiga para o próximo passo para verificar se todos os pods estão em execução.
Confirmando o Deploy
Para saber se o deploy ocorreu tudo bem, execute o comando abaixo e verifique se todos os pods estão com status de running ou completed.
kubectl --kubeconfig=kubeconfig.yaml get pods
O resultado esperado deve ser parecido com o da imagem abaixo.
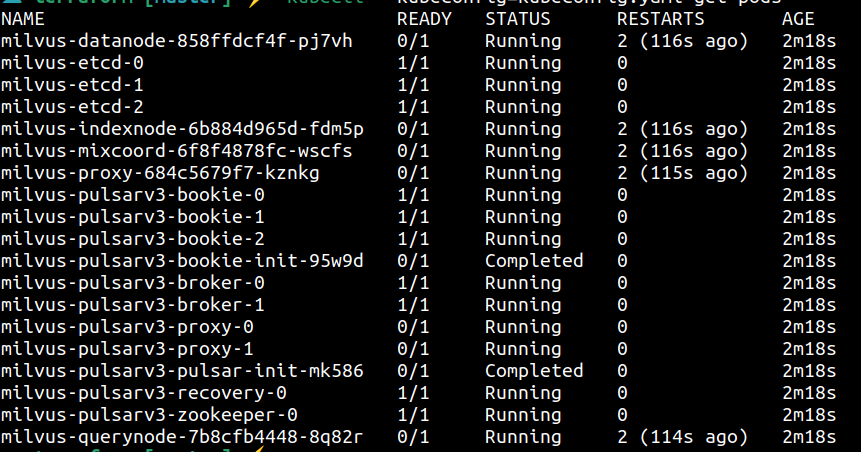
Se os pods permanecerem no status pending por alguns minutos, pode ser necessário solicitar um aumento na cota de recursos da sua conta. Para isso, abra um ticket no suporte detalhando o problema e solicitando o ajuste da cota.
Casos de Uso
Nesta seção, será apresentado como utilizar o Milvus para armazenar imagens e posteriormente realizar buscas por similaridade. Para isso, será utilizado o dataset MNIST e a linguagem de programação Python. Utilize um único arquivo Python ou um Jupyter Notebook para executar os códigos apresentados a seguir.
Instalando Dependências
Primeiro, é necessário instalar as seguintes dependências:
pip install torchvision transformers pymilvus matplotlib
Extraindo as Características das Imagens
Com as dependências instaladas, é necessário extrair as características das imagens e transformá-las em vetores de embeddings. Para isso, será criado uma classe que utiliza o modelo ResNet50 para extrair as embeddings:
import torch
import torchvision.transforms as transforms
from torchvision import models
class GenerateEmbeddings:
def __init__(self):
self.model = models.resnet50(pretrained=True)
self.model = torch.nn.Sequential(*list(self.model.children())[:-1])
self.model.eval()
self.transform = transforms.Compose([
transforms.Resize(224),
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def __call__(self, image):
image = image.unsqueeze(0)
with torch.no_grad():
embedding = self.model(image)
embedding = embedding.view(embedding.size(0), -1)
embedding = embedding.squeeze().numpy()
return embedding
Conectando com o Milvus
Com a classe de extração de embeddings criada, conecte-se ao Milvus e crie a coleção onde as imagens serão armazenadas. Como o modelo utilizado gera embeddings com dimensão 2048, será utilizado esse valor como dimensão do vetor na coleção do Milvus.
Para saber em qual host o Milvus está hospedado, execute o comando abaixo no terminal. Isso listará os serviços utilizados pelo Milvus. Dentre eles, haverá um com o nome "Milvus", que será do tipo LoadBalancerl ele terá um IP externo, que deverá ser utilizado para se conectar ao Milvus.
kubectl --kubeconfig=kubeconfig.yaml get svc
from pymilvus import MilvusClient
client = MilvusClient(uri="http://host_do_seu_milvus:19530")
collection_name="image_embeddings"
if client.has_collection(collection_name=collection_name):
client.drop_collection(collection_name=collection_name)
client.create_collection(
collection_name=collection_name,
vector_field_name="vector",
dimension=2048,
auto_id=True,
enable_dynamic_field=True,
metric_type="COSINE",
)
Inserindo as Imagens no Milvus
Com a coleção criada, já é possivel inserir as imagens.
A execução desse bloco de código pode levar alguns minutos.
from torchvision import datasets
generateEmbedding = GenerateEmbeddings()
transform = generateEmbedding.transform
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
for idx in range(2000):
image, label = train_dataset[idx]
embedding = generateEmbedding(image)
client.insert(
"image_embeddings",
{"vector": embedding, "image_index": idx, "label": label},
)
client.flush(collection_name=collection_name)
Buscar Imagem no Milvus
Após inserir as imagens na coleção, já é possivel realizar buscas por similaridade. Para isso, serão criados duas funções: uma para exibir as imagens e outra para realizar a busca.
import matplotlib.pyplot as plt
import numpy as np
def show_image(image, label, distance=None):
if hasattr(image, 'numpy'):
image = image.numpy()
if image.shape[0] == 3:
image = np.transpose(image, (1, 2, 0))
plt.imshow(image)
plt.title(f'Label: {label} - Dist: {distance}') if distance else plt.title(f'Label: {label}')
plt.show()
def search_image(milvus_client, query_data, train_dataset, top_k=3):
image, label = query_data
generateEmbedding = GenerateEmbeddings()
queryEmbedding = generateEmbedding(image)
print("Query Image: ")
show_image(image, label)
milvus_client.load_collection(collection_name=collection_name) # Carrega os dados do OBJS para a memória
results = milvus_client.search(
"image_embeddings",
data=[np.array(queryEmbedding)],
output_fields=["label", "image_index"],
limit=top_k,
search_params={"metric_type": "COSINE"},
)
print("Results: ")
for result in results:
for hit in result:
distance = hit.get("distance")
image = train_dataset[hit.get("entity").get("image_index")][0]
lb = hit.get("entity").get("label")
show_image(image, lb, distance)
Para realizar a busca, basta executar o comando abaixo, passando o client do Milvus, a imagem de consulta (no exemplo, o primeiro item do dataset de teste) e o dataset de treino para visualização dos resultados:
search_image(client, test_dataset[0], train_dataset=train_dataset)
Os resultados serão exibidos conforme as imagens abaixo:
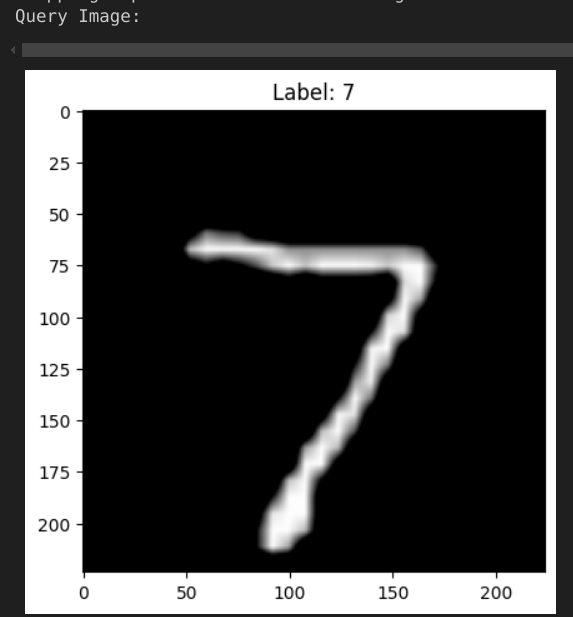
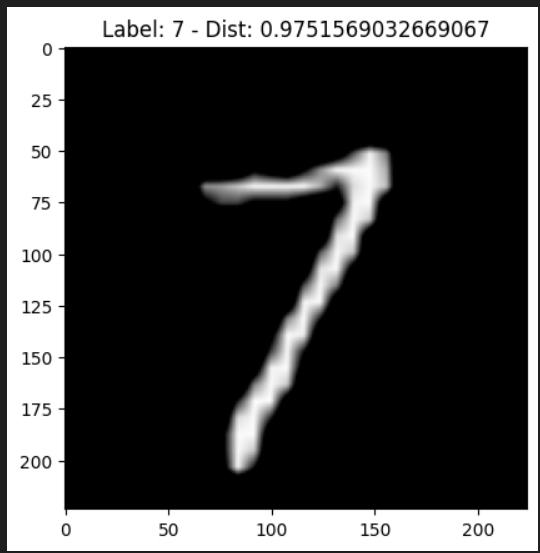
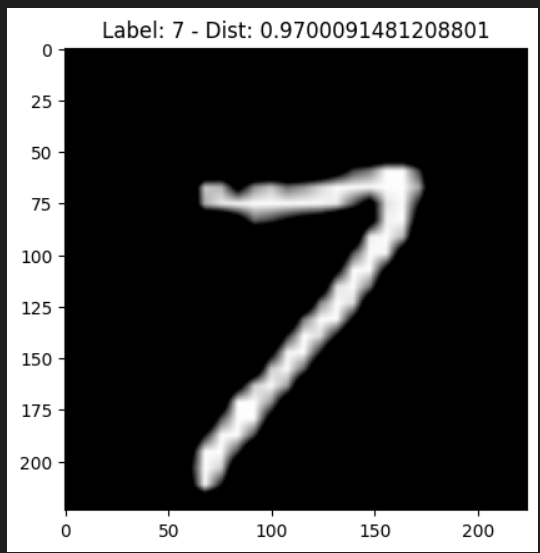
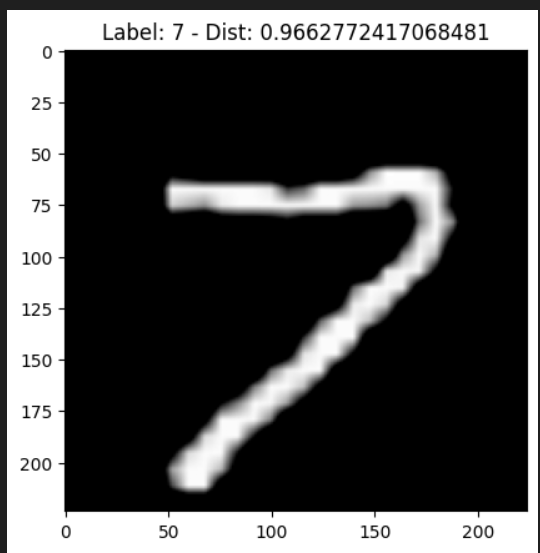
Desinstalando Milvus
Caso queira desinstalar o milvus do cluster, execute o comando:
helm --kubeconfig=kubeconfig.yaml uninstall milvus
Caso for excluir o cluster, lembre-se de desinstalar o Milvus e apagar os volumes provisionados. Isso pode ser realizado executando o seguinte comando:
kubectl --kubeconfig=kubeconfig.yaml delete pvc --all